
Robot learning with priors based on latent variables
Improving data efficiency is one of the central challenges in robot learning because task examples and demonstrations are often expensive to acquire. One way to enable robots to learn from limited data is to employ domain priors. To effectively represent and incorporate these priors, this research explores approaches based on latent variables. The introduction of latent variables allows for a low-dimensional representation of task data and enforced structures, alleviating computational challenges in dealing with raw sensory data. Latent variables can also be used as a flexible intermediate representation to retain and transfer some useful structures to a target task. Lastly, with a prior design, latent variables might correlate the raw data to some intepretable values, or even abstract concepts to represent quite general model priors.
Priors on Temporal Relation
For one example, imagine the robot accesses a set of rolling ball data in the form of video streams. It is apparent that, despite of the high-dimensionality of raw data, the generation of rolling-ball pixels is governed by a low-dimensional (latent) process. The latent variables and their temporal relation can be simultaneously extracted through unsupervised learning with a variational treatment:
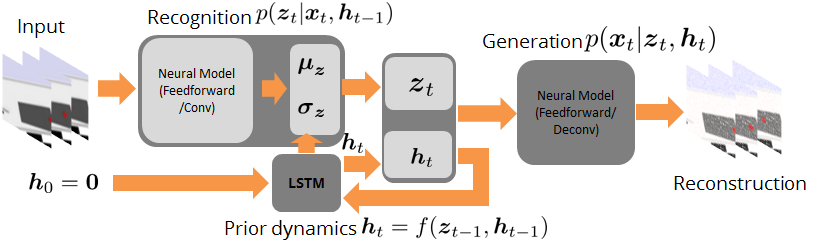
The learning routine ends with a posterior model which transforms raw data sequence to latent variables, a prior model which predicts the next latent variable if there is no observation, and a generation model which eventually allows to sample sequences similar to the learned data. Such an idea is not restricted to this rolling ball example. It is actually applicable to another example with an underlying dynamical process, e.g., the generation of dynamical handwriting images:






Meanwhile, the extracted dynamics might be useful in addressing relevant tasks. For instance, the prior knowledge about the rolling ball movement could facilitate the learning of a ball-striking task, in which the robot needs to anticipate the ball trajectory and move a paddle to hit the ball towards a target. The latent variable representation makes the task learning much easier in a low-dimensional space:
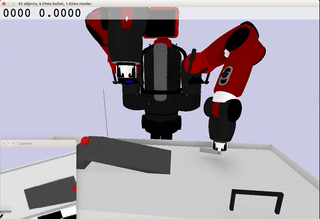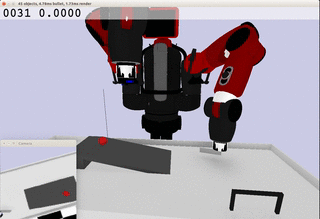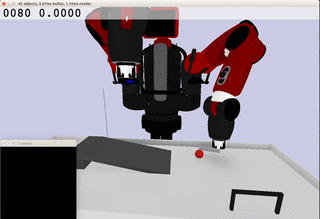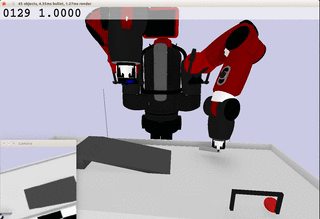
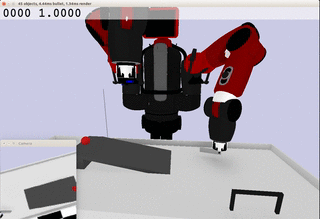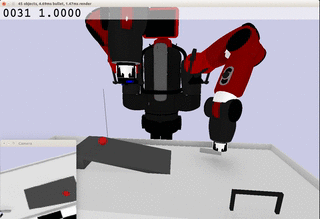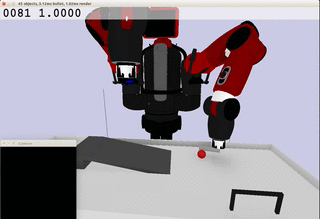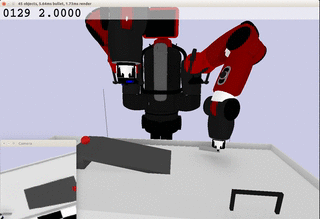
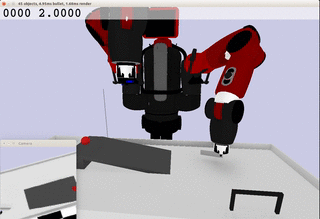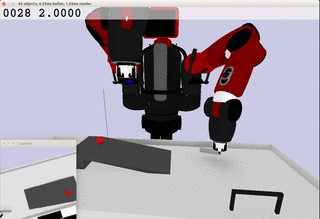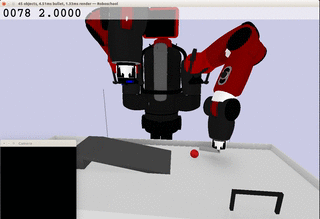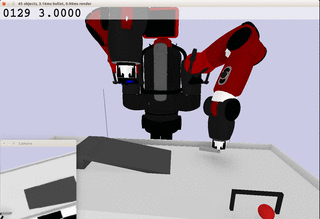
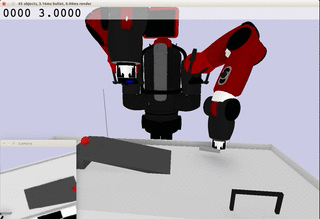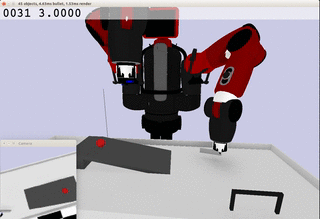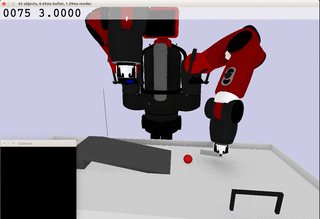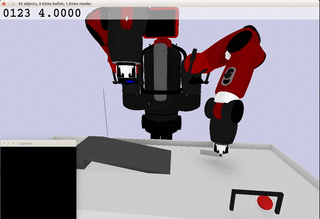
Note the robot does not need to always have the access to the visual input. In fact, the prior model allows robot to have an internal prediction about the future sensory input after the camera is switched off and still scores the goal with a model-based control.
Priors on Data Modalities
Another type of prior is explored to bridge task examples of different modalities. For instance, the robot is demonstrated with handwriting examples of two modalities: letter images and arm joint movements to form the letter trajectories. Both modalities of data can be of a high-dimensionality and each can be transformed to a latent representation as a compressed form. Moreover, the latent variable can be regarded as an abstract representation of the learning letter. This implies the latent variables from images and motion trajectories should be identical, because the two types of demonstrations are describing the same task abstraction through the lens of different sensor modalities.
The prior about this modal associativity can be enforced in the latent space of two deep generative models:
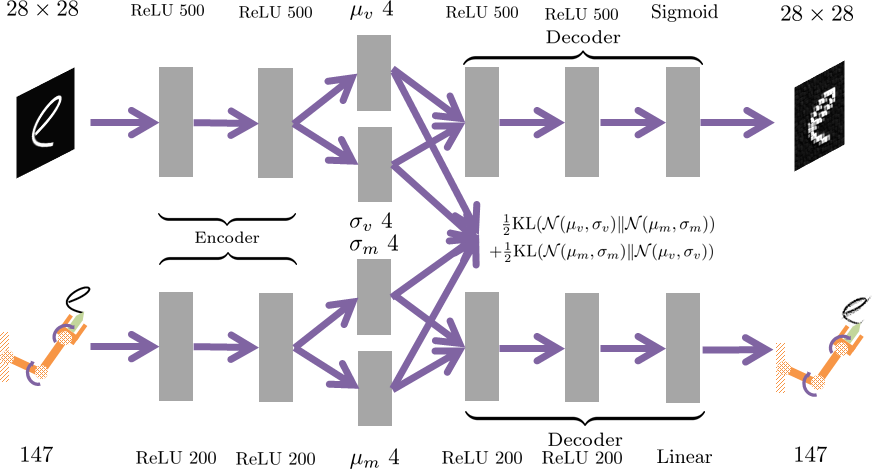
The latent space can thus be considered as overlapped manifolds that intepolate both letter images and motions:
Exploiting such an associativity, one can obtain an end-to-end controller which infers handwriting motion from letter images:
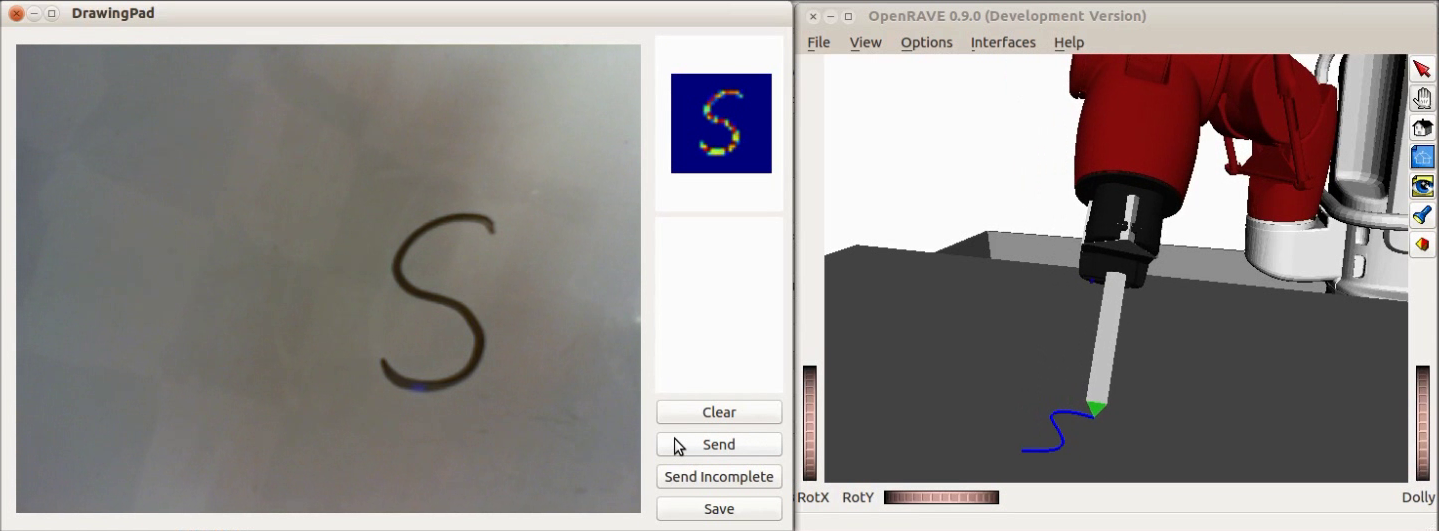
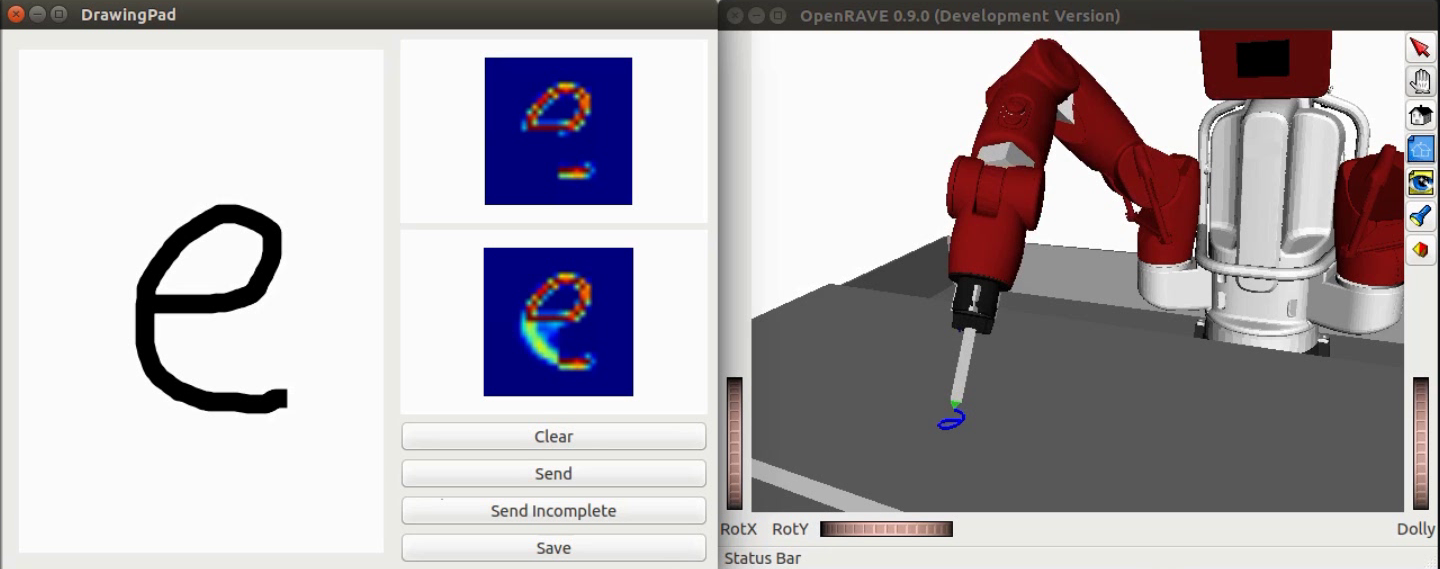
Note the full generative model of image modality can help when the input is not complete: one can first explore in the latent space to find the variable that complements the occluded part and then generate arm motion accordingly.
Find more in
Papers:
Associate Latent Encodings in Learning from Demonstrations
Repositories: